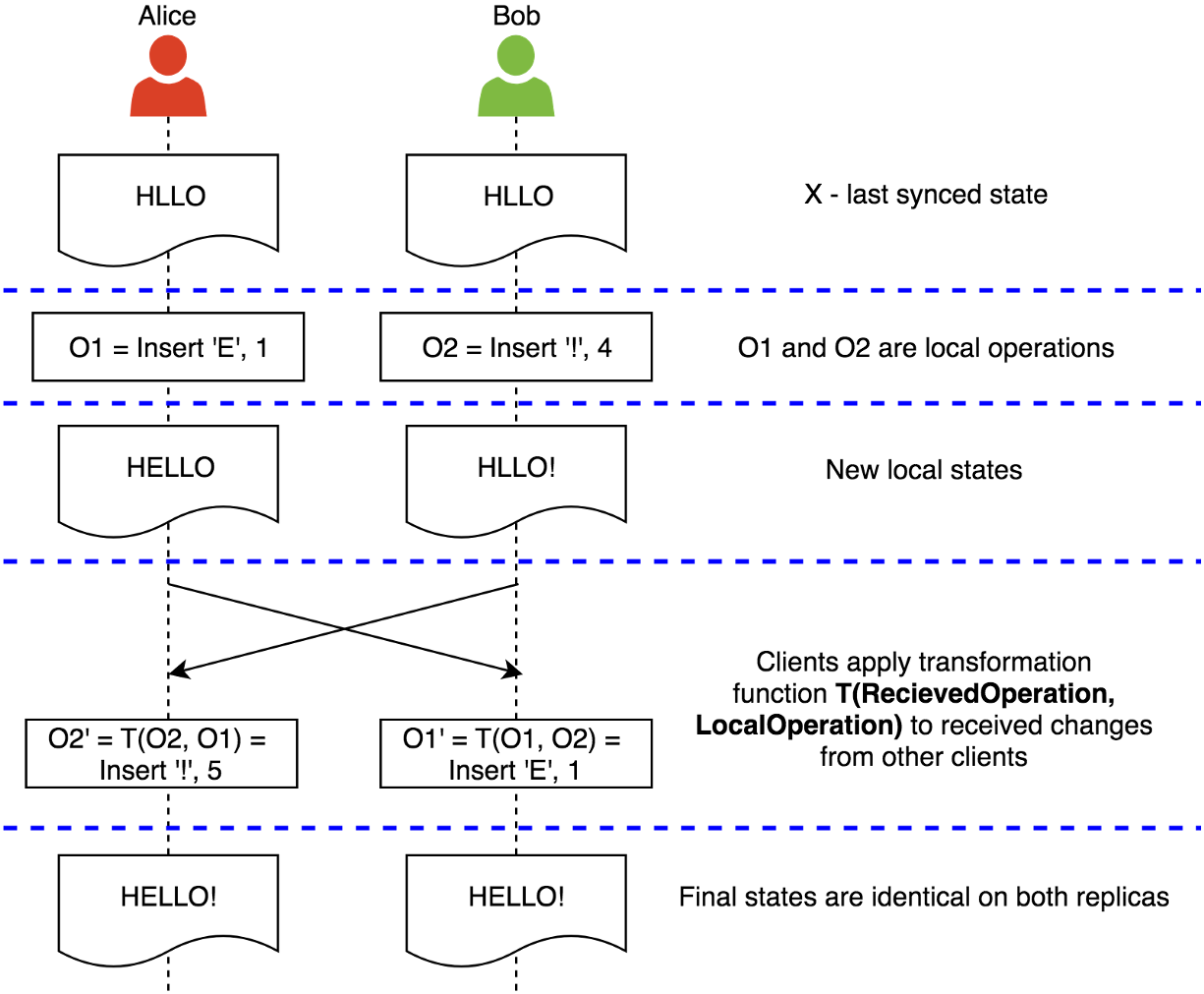
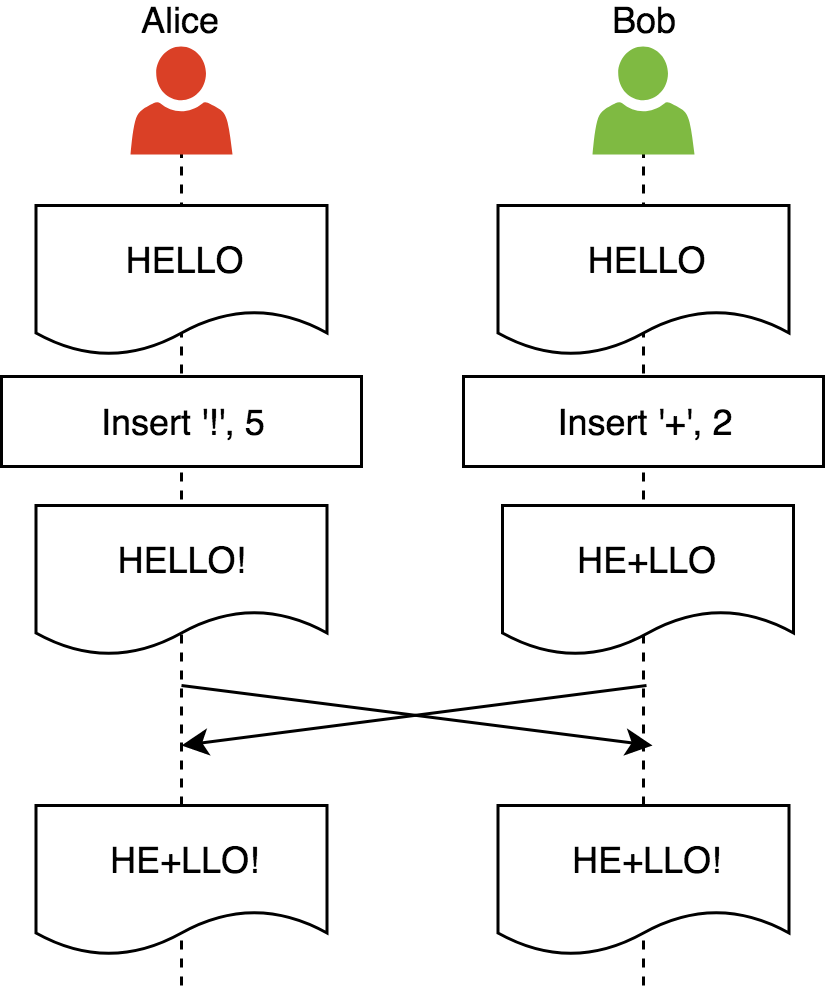
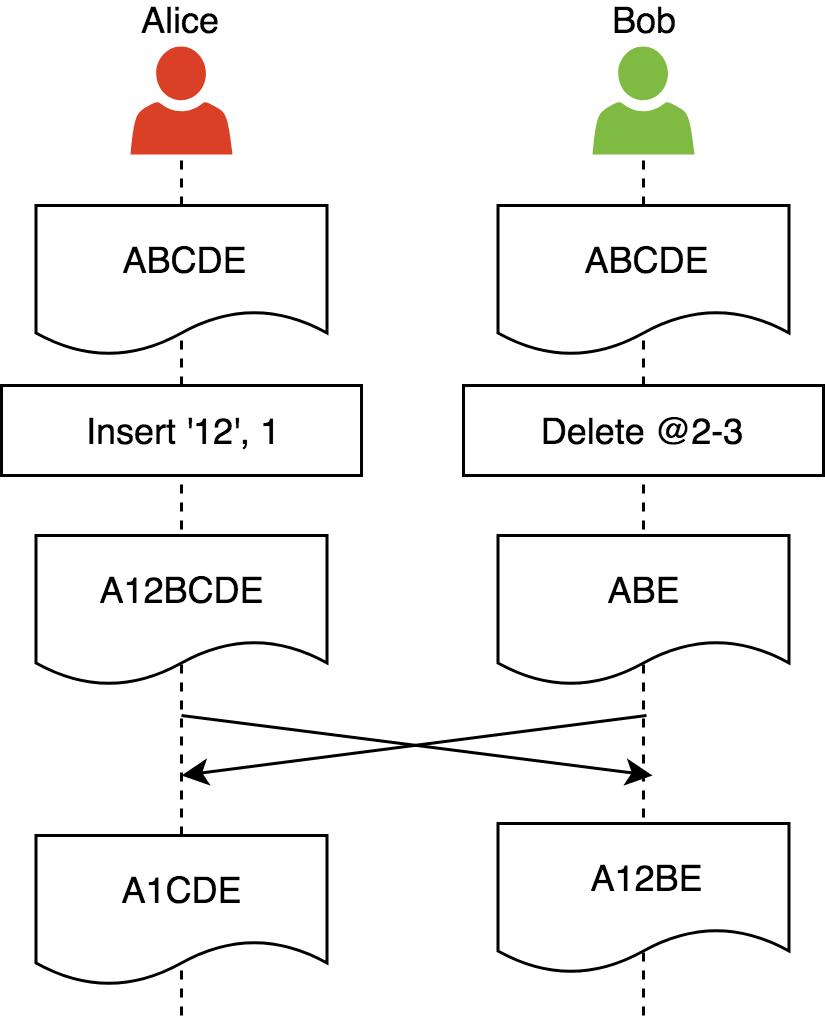
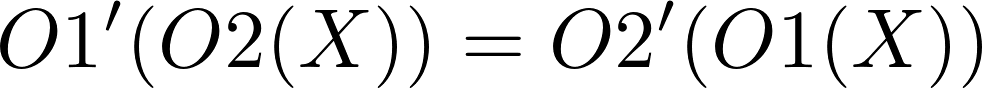Threads and Memory
At its heart, multithreaded programming seems simple enough. Instead of having just one processing
unit doing work sequentially, you have two or more executing simultaneously. Because the processors
might be real hardware or might be implemented by time-multiplexing a single processor, the term
“thread” is used instead of processor. The tricky part of multithreaded programming is how threads
communicate with one another.
The most commonly deployed multithreaded communication
model is called the shared memory model.
There are four conditions needed for a race to be possible.
The first condition is that there are memory locations that are accessible from more than one thread.Typically, locations are global/static variables (as is the case of totalRequests) or are heap memory
reachable from global/static variables.
The second condition is that there is a property associated with these shared memory locations that is needed for the program to function correctly. In this case, the property is that totalRequests accurately represents the total number of times any thread has executed any part of the increment statement.Typically, the property needs to hold true (that is, totalRequests must hold an accurate count) before an update occurs for the update to be correct.
The third condition is that the property does not hold during some part of the actual update. In this particular case, from the time totalRequests is fetched until the time it is stored, totalRequests does not
satisfy the invariant.
The fourth and final condition that must occur for a race to happen is that another thread accesses the memory when the invariant is broken, thereby causing incorrect behavior.
Soluation
Locks
The most common way of preventing races is to use locks to prevent other threads from accessing memory associated with an invariant while it is broken. This removes the fourth condition I mentioned, thus making a race impossible.
The most common kind of lock goes by many different names. It is sometimes called a monitor, a
critical section, a mutex, or a binary semaphore, but regardless of the name, it provides the same basic functionality.
static object totalRequestsLock = new Object(); // executed at program
// init
…
System.Threading.Monitor.Enter(totalRequestsLock);
totalRequests = totalRequests + 1;
System.Threading.Monitor.Exit(totalRequestsLock);While this code does fix the race, it can introduce another problem. If an exception happens while the lock is held, then Exit will not be called. This will cause all other threads that try to run this code to block forever. In many programs, any exception would be considered fatal to the program and thus what happens in that case is not interesting. However, for programs that want to be able to recover from exceptions, the solution can be made more robust by putting the call to Exit in a finally clause:
Lock is have C# common implementation of above issues.
lock (x) { // Your code… }
object __lockObj = x;
bool __lockWasTaken = false;
try
{
System.Threading.Monitor.Enter(__lockObj, ref __lockWasTaken);
// Your code…
}
finally
{
if (__lockWasTaken) System.Threading.Monitor.Exit(__lockObj);
}Avoid using the same lock object instance for different shared resources, as it might result in deadlock or lock contention
since the code uses a try…finally block, the lock is released even if an exception is thrown within the body of a lock statement.
but If exception was thrown in your code ,Allowing the program to continue without trying to fix the invariant is a bad ideaThe first important observation is that locks provide mutual exclusion for regions of code, but generally programmers want to protect regions of memory. In the totalRequests example, the goal is to make certain an invariant holds true on totalRequests (a memory location). However, to do so, you actually place a lock around a region of code (the increment of totalRequests). This provides mutual exclusion over totalRequests because it is the only code that references totalRequests. If there was other code that updates totalRequests without entering the lock, then you would not have mutual exclusion for the memory, and consequently the code would have race conditions.
Make lock on as small portion of code as possible.
Taking Locks on Reads
lock for read is required to read correct value depending on implementation.
Deadlock
Another reason to avoid having many locks in the system is deadlock. Once a program has more than one lock, deadlock becomes a possibility. For example, if one thread tries to enter Lock A and then Lock B, while simultaneously another thread tries to enter Lock B and then Lock A, it is possible for them to deadlock if each enters the lock that the other owns before attempting to enter the second lock.
From a pragmatic perspective, deadlocks are generally prevented in one of two ways. The first (and best) way to prevent deadlock, is to have few enough locks in the system that it is never necessary to take more than one lock at a time.
If this is impossible, deadlock can also be prevented by having a convention on the order in which locks are taken. Deadlocks can only occur if there is a circular chain of
threads such that each thread in the chain is waiting on a lock already acquired by the next in line. To prevent this, each lock in the system is assigned a “level”, and the program is designed so that threads always take locks only in strictly descending order by level. This protocol makes cycles involving locks, and therefore deadlock, impossible. If this strategy does not work (can’t find a set of levels), it is likely
that the lock-taking behavior of the program is so input-dependent that it is impossible to guarantee that deadlock can not happen in every case. Typically, this type of code falls back on timeouts or some kind of deadlock detection scheme.
Deadlock is just one more reason to keep the number of locks in the system small. If this cannot be done, an analysis must be made to determine why more than one lock has to be taken simultaneously.
Remember, taking multiple locks is only necessary when code needs to get exclusive access to memory protected by different locks. This analysis typically either yields a trivial lock ordering that will avoid deadlock or shows that complete deadlock avoidance is impossible.
The Cost of Locks
Another reason for avoiding locks is system cost for entering and leaving lock. The special instruction used lock is expensive(typically 10 to 100 times than normal ). There are two main reasons for this expense, and they both have to do with issues arising on a true multiprocessor system.
The first reason is that the compare/exchange instruction must ensure that no other processor is also trying to do the same thing.
In addition to the raw overhead of entering and leaving locks, as the number of processors in the system grows, locks become the main impediment in using all the processors efficiently. If there are too few locks in the program, it is impossible to keep all the processors busy since they are waiting on memory that is locked by another processor.
On the other hand, if there are many locks in the program, it is easy
to have a “hot” lock that is being entered and exited frequently by many processors. This causes the memory-flushing overhead to be very high, and throughput again does not scale linearly with the number of processors. The only design that scales well is one in which worker threads can do significant work without interacting with shared data.
Inevitably, performance issues might make you want to avoid locks altogether. This can be done in certain constrained circumstances, but doing it correctly involves even more subtleties than getting mutual exclusion correct using locks. It should only be used as a last resort, and only after understanding the issues involved.
it requires a significantly higher degree of discipline to build a correct multithreaded program. Part of this discipline is ensuring through tools like monitors that all thread-shared, read-write data is protected by locks.