Functional Requirement
- Users can change a document at the same time without any conflict
- Users can give permission(view, editor) for a document
- Users can make import and export a document
- A user can add a comment to the document
- Could be a notification (Email, GCM notification)
Design Constraint
- Concurrency: A lot of people are working on the same document
- Latency: People are working in different places and they connect throughout the internet, so there is a latency between each and every know clients or users when they are sharing the same document.
- 200M User, Daily active % 10 = 20M User
- Average 1 MB usage ~ 1MB x 20M user = 20 BP per day usage
Google Docs users get a lot of storage space with their accounts, but it’s not unlimited. Each account can have up to:
- 5,000 documents of up to 500 kilobytes each
- 1,000 spreadsheets of up to 1 megabyte each
- 5,000 presentations of up to 10 megabytes each
First, we need to understand some logic that a lot of users can change a document at the same time without any conflict.
Operational Transformation
Operational Transformations as an algorithm for automatic conflict resolution.
OT provide mechanism that allow multiple users to work on same document on same time without conflit.
OT: Transform parameter of editing operation according the effects of previously executed operations concurrent operation so that transformed object can achieve the correct effect and document consistency .
Operational Transformations as an algorithm for automatic conflict resolution
1. Introduction
Automatic conflicts resolution algorithms in distributed systems with more than one leader nodes (In this article by leader node we mean a node which accepts data changing requests) is quite interesting research field. There are different approaches and algorithms in this area with their own trade-offs and in this article we will focus on Operational Transformation technology which is aimed to solve conflicts in collaborative editing applications like Google Docs or Etherpad.
Collaborative editing is a difficult task to solve from a development point of view because clients can be doing changes in the same parts of text at almost the same time. To imitate immediate response each client has to maintain its own local copy of the document, otherwise clients would have wait till their changes are synced with other clients and that can and will take a noticeable amount of time. So the main issue in collaborative editing is to ensure consistency between local replicas i.e. all replicas have to converge to the identical, correct version of the document (Note we can not require all replicas to have an identical copy of the document at some point in time as the editing process can be endless).
1.1 First versions of Google Docs
First versions of Google Docs (as well as other similar applications) used a comparison of document versions. Imagine we have two clients — Alice and Bob and their documents are synchronized. When the server receives changes from Alice it calculates the diff between her version and its and tries to merge them. Then the server sends the merged version to Bob. If Bob has his own unsent changes he tries to merge received server’s version with his. And the process repeats.
Quite often this approach doesn’t work well. For example, imagine that Alice, Bob, and server start from the synchronized document “The quick brown fox”.
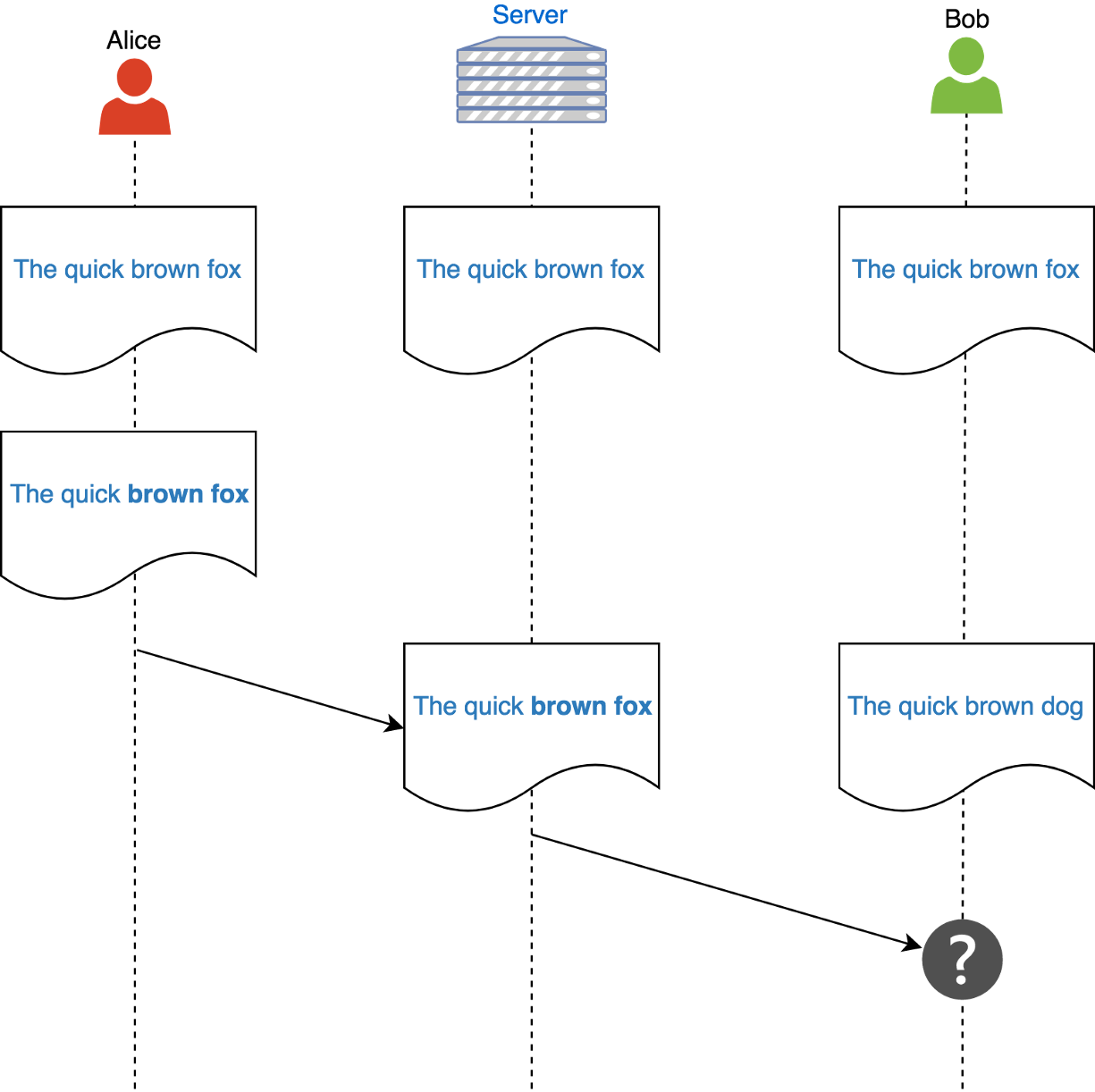
Alice bolds the words “brown fox” and at the same time Bob changes “fox” to “dog”. Alice’s changes arrived first at the server, it applies and sends changes further to Bob. The correct result of the merge should be “The quick brown dog”, but merging algorithms do not have enough information to perform the correct merge. From their perspective “The quick brown fox dog”, “The quick brown dog”, “The quick brown dog fox” are all correct and valid results. (In such cases in git you would have merge conflicts and you would have to merge manually). So that is the main problem — we can not rely on the merge with such an approach.
1.2 Latest Google Docs versions
Latest Google Docs versions follow another approach — a document is stored as a sequence of operations and they are applied in order (by order here we mean a total order) instead of comparing versions of documents.
Ok, now we need to understand when to apply changes — we need a collaboration protocol. In Google Docs all operations are down to 3 possible types:
- Insert text
- Delete text
- Apply style
When you edit a document all changes are appended to the changelog in one of those 3 types and the changelog is replayed from some point when you open a document.
(First (public) Google project with OT support was Google Wave and its set of possible operations was much richer)
1.3 Example
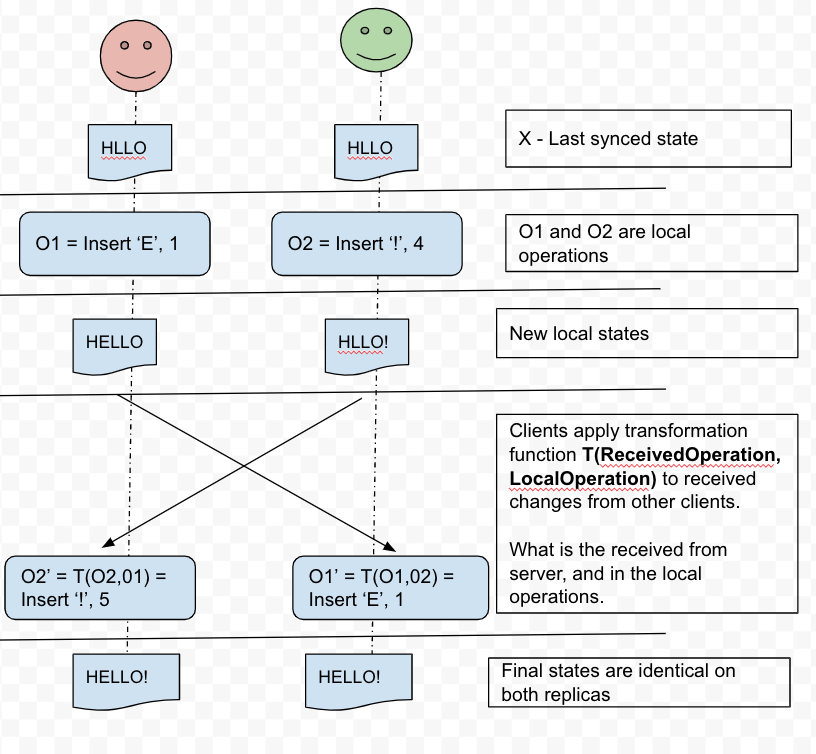
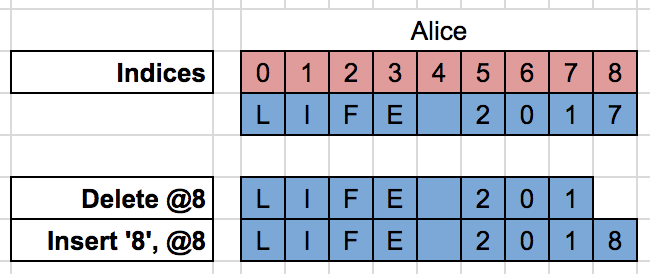
Let Alice and Bob start from a synchronized document “LIFE 2017”.
Alice changes 2017 to 2018 and that actually creates 2 operations:
At the same time Bob changes the text to “CRAZY LIFE 2017”:
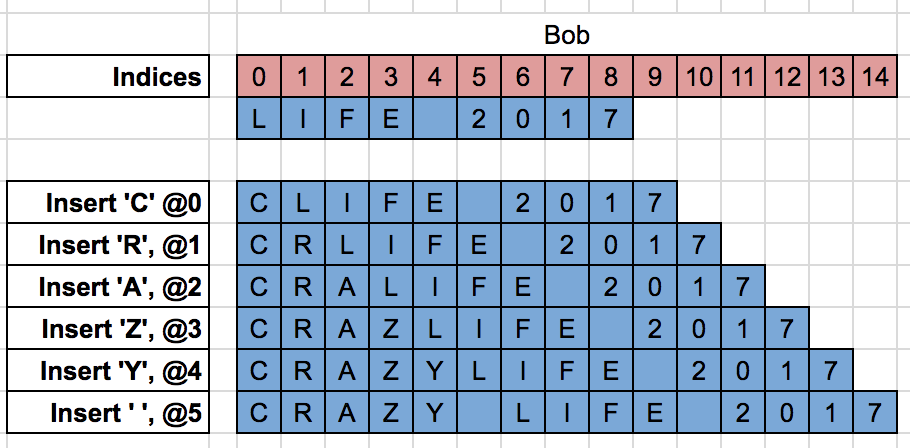
If Bob just applies Alice’s delete operation when he receives it then he gets an incorrect document (the digit 7 should have been deleted instead):

Bob needs to transform the delete operation accordingly to his local changes to get the correct state of the document :


Now it is perfect.
To make it more formal, let’s consider the following example:
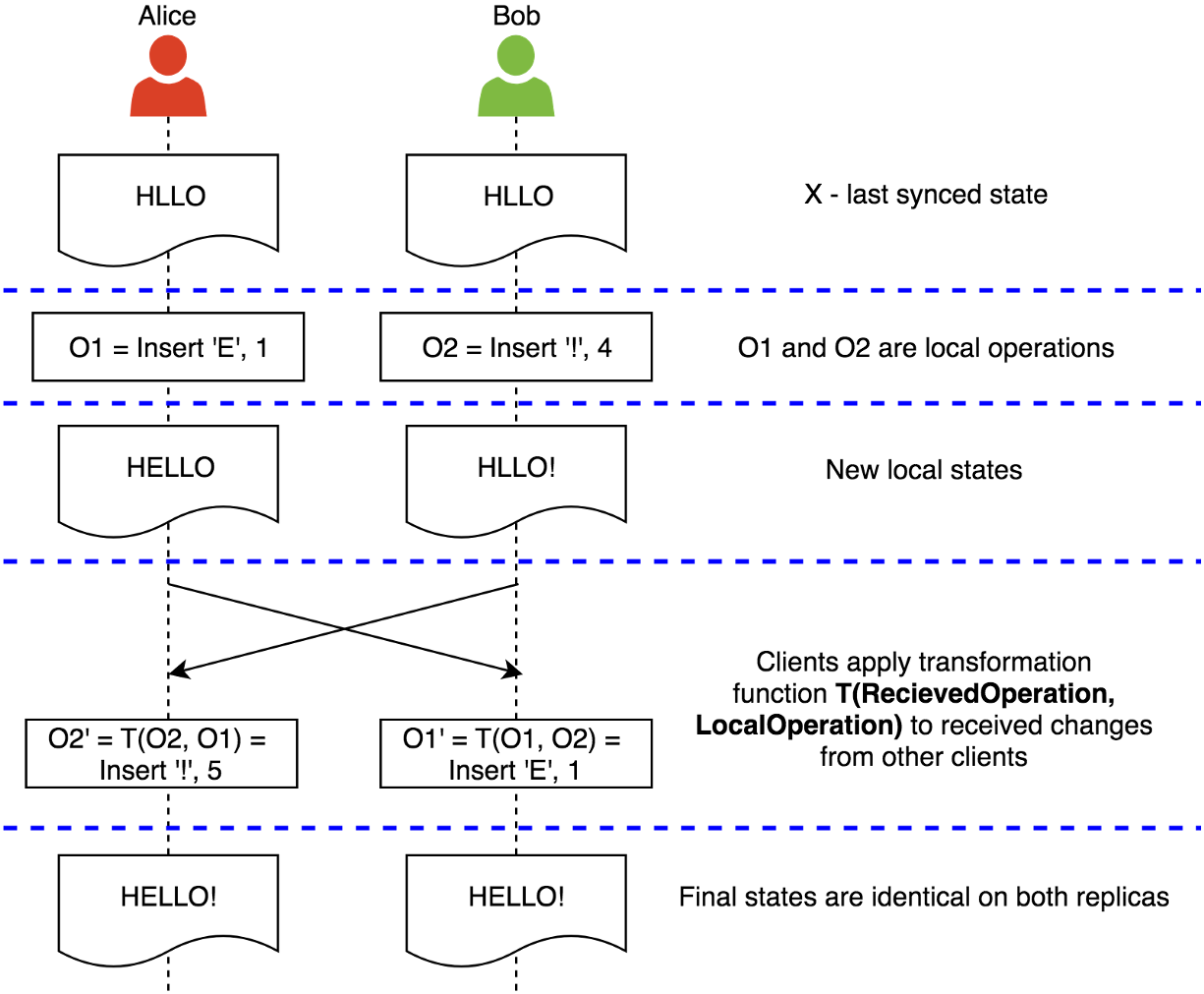
then
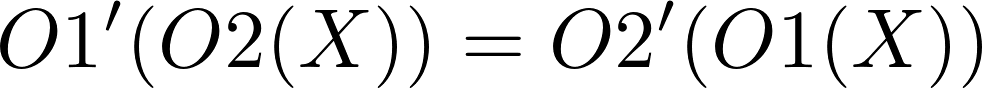
Voila! Described algorithm is the Operational Transformation.
2. Operational Transformation
2.1 Consistency models
Few consistency models have been developed to provide consistency for OT. Let’s consider one of them — CCI model.
The CCI model consists of the following properties:
- Convergence: all replicas of the same document must be identical after execution of all operations
Alice and Bob start from the same document, then they do local changes and replicas diverge (thus high responsiveness is achieved). Convergence property requires Alice and Bob to see the same document after they received changes from each other.
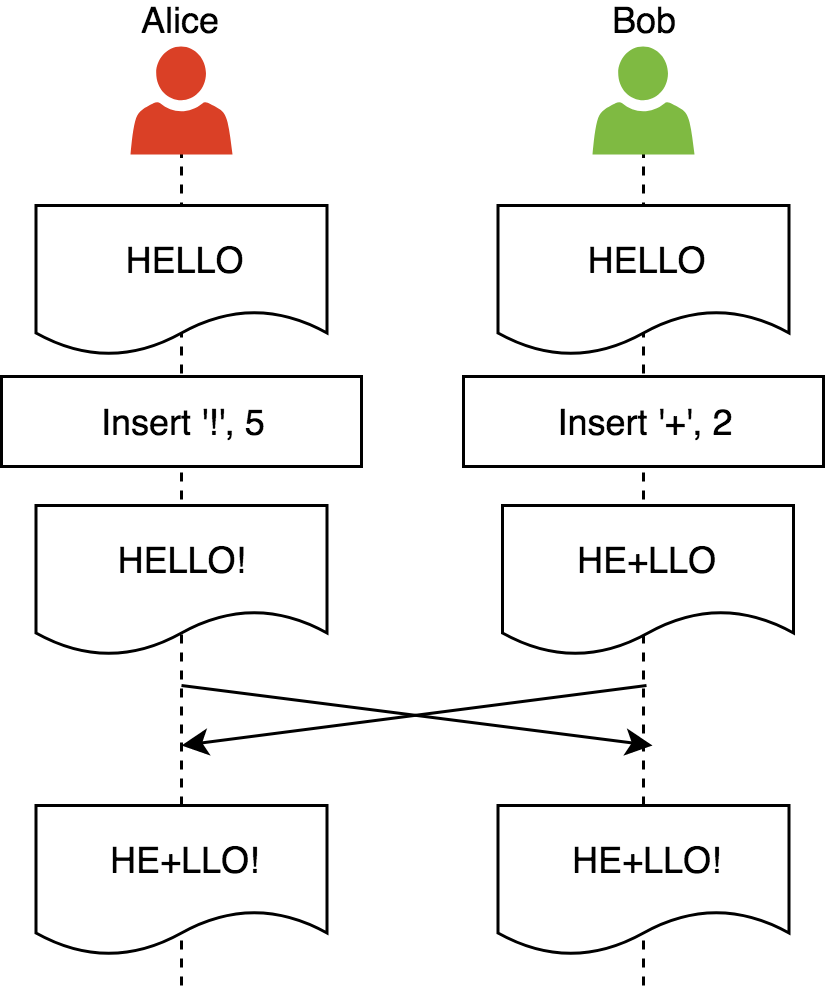
2. Intention preservation: ensures that the effect of executing an operation on any document state will be the same as the intention of the operation. An intention of operation is defined as the effect of its execution on a replica it was created.
Let’s consider an example where this property is violated:
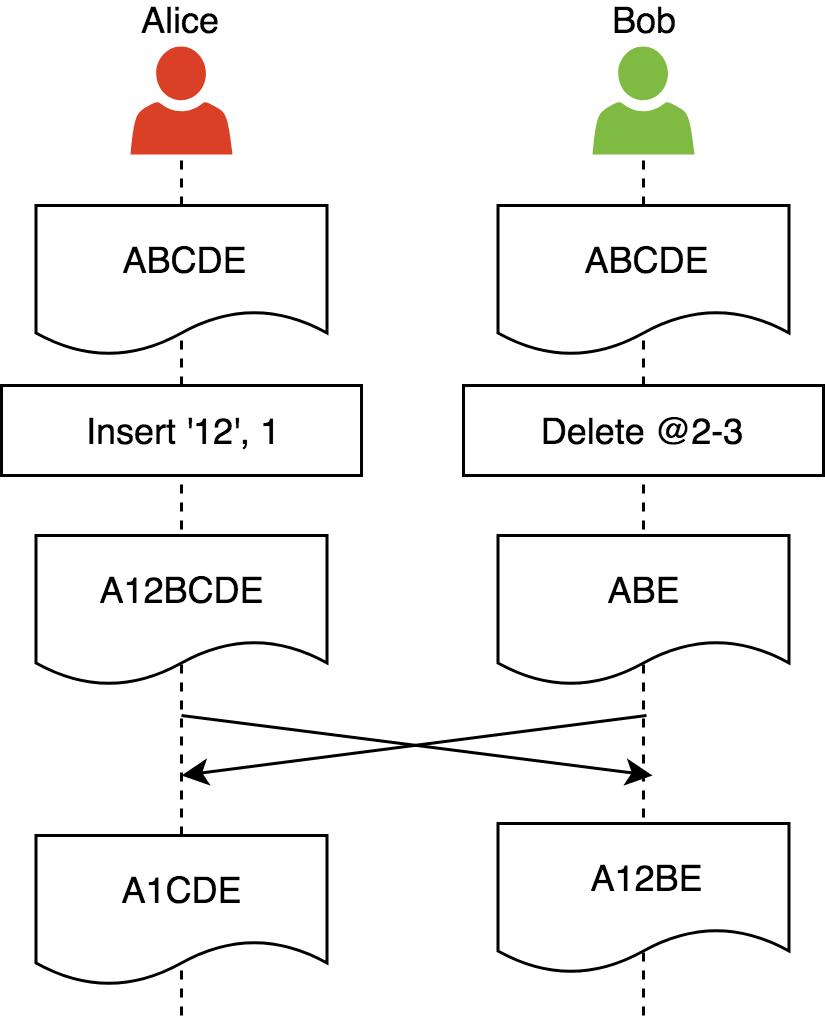
Alice and Bob start from the same document state, then do their local changes. The intention of Alice’s operation is to insert ‘12’ at position 1 and the intention of Bob’s operation is to delete ‘CD’. After synchronization Bob’s intention is violated. We can also observe replicas have diverged, but that is not a requirement for the intention preservation property. Exercise: what is the correct final state in this example?
3. Causality preservation: operations must be executed accordingly to their natural cause-effect order during the process of collaboration (based on the happened-before relation).
Let’s consider the example where this property is violated:
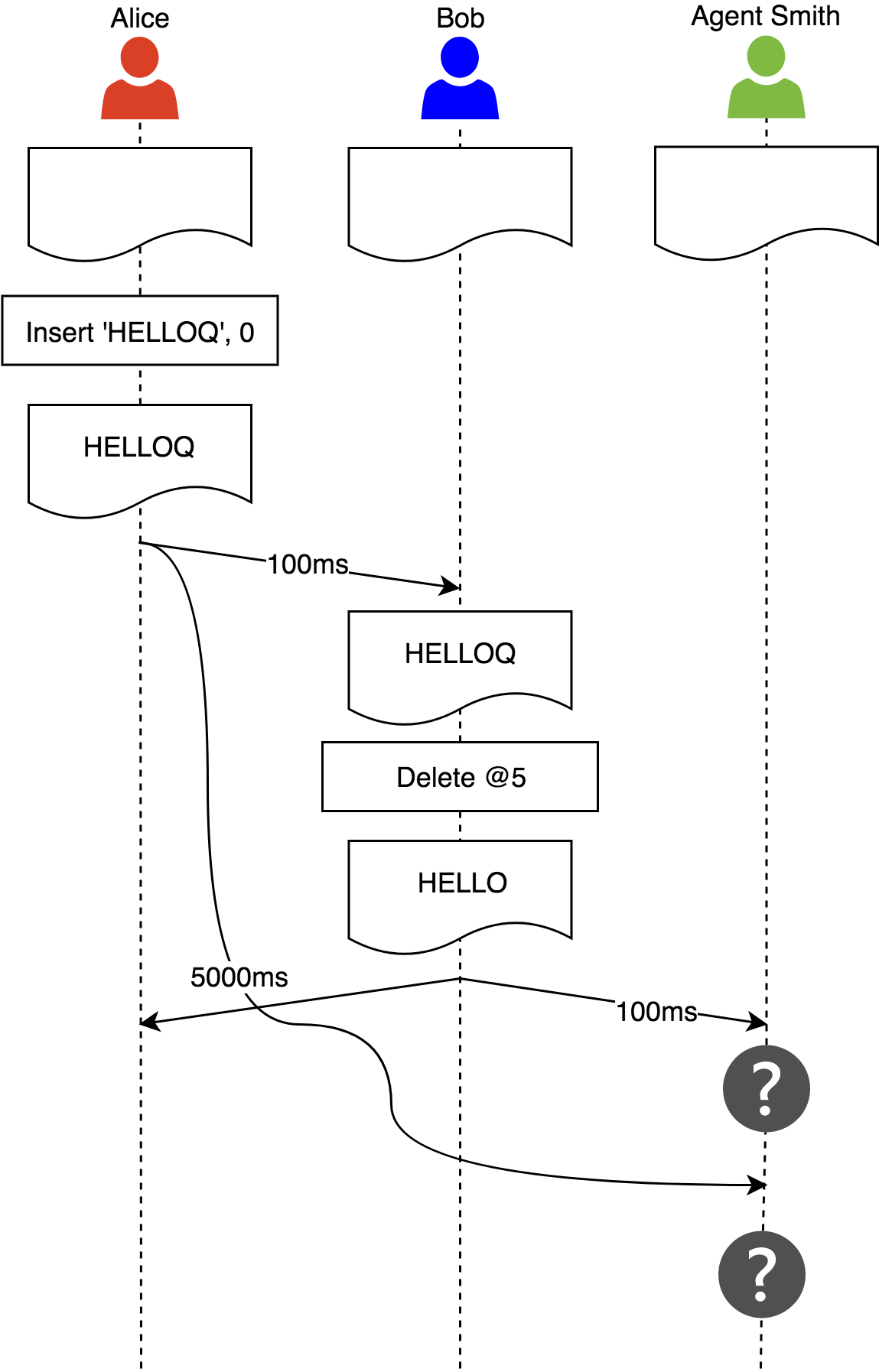
Alice, Bob, Agent Smith start from the same document state. Alice does her change and sends it to other clients. Bob receives it first and corrects the typo and sends this change to other clients. Due to a network lag, Agent Smith first receives the operation from Bob, which is to delete a symbol which doesn’t exist yet in his replica.
OT can’t ensure this property so other algorithms like Vector clock can be used.
2.2 OT Design
One of the OT design strategies is to split it into 3 parts:

- Transformation control algorithms: responsible for determining when an operation (transformation target) is ready for transformation, which operations (transformation reference) should be transformed against, and in which order should transformations be carried out
- Transformation functions: responsible for performing actual transformations on the target operation according to the impact of the reference operation
- Properties and conditions: define the relationships between transformation control algorithms and functions, and serve as OT algorithm correctness requirement
2.3 Transformation functions
Transformation functions can be divided into two types:
- Inclusion/Forward transformation: to transform operation Oa before Ob so that the effect of Ob is included (e.g. two insertions)
- Exclusion/Backward transformation: to transform operation Oa before Ob so that the effect of Ob is excluded (e.g. insertion after deletion)
Here is an example of transformation functions which work with character changes:
3. Collaboration protocol in Google Docs
Let’s consider how Google Docs collaboration protocol works in more details.
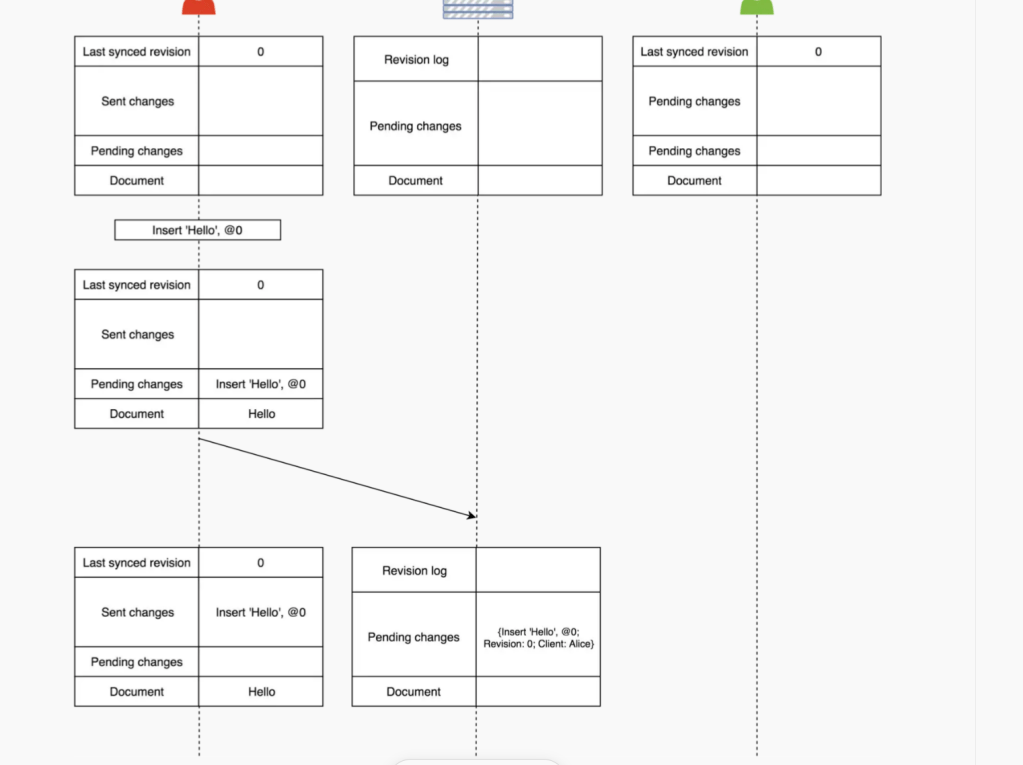
Each client maintains the following information:
- Last synced revision (id)
- All local changes which have not been sent to the server (Pending changes)
- All local changes sent to the server but have not been acknowledged (Sent changes)
- Current document state visible to the user
- The server maintains the following information:
- List of all received but have not been processed changes (Pending changes)
- Log of all processed changes (Revision log)
- State of the document on the time of last processed change
- Assume we have Alice, Server, Bob and they start from a synchronised empty document.
High Level Design
Flow
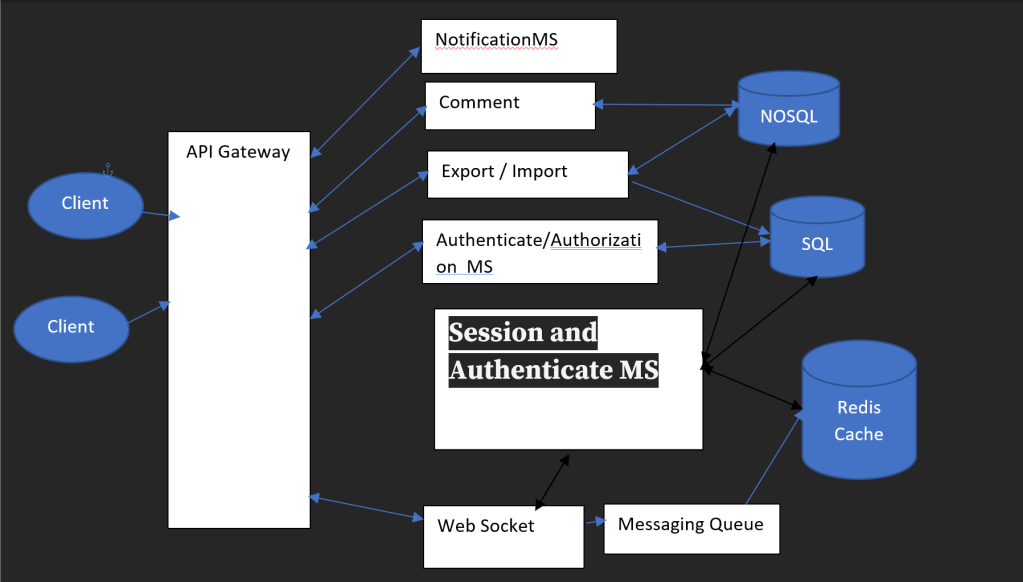
We have 3 clients.
API GATEWAY :
Is an API management tool that sits between a client and collection of backend service.
An API Gateway takes all the API calls from clients, then routes them to the appropriate microservice with request routing, composition, and protocol translation.
In this case, clients interact with the API GATEWAY for any operation to be performed. The gateway can connect first Authenticate and permission service whether understanding you have a permit or not in the current documents.
Advantages
- Single entry point & API composition
- Security
- Dynamic Service Discovery
- Service Partition HIdden
- Hiding MS
- Circuit Breaking
Comments Service
We might have a lot of comments about sharing documents. We can choose a line or position or a section and we can put a comment.
The dataType could be K-V.
K: document_id, V: Json object relevant to the comment. {line:1, position: 123, comment: “hey”, user_id: 123}
And we can use a NoSQL DB for comment service. Because we have a lot of huge data and we don’t need serious relations. K-V is enough. (Mongo, DynamoDB, etc. )
Authentication Service
Provides our permission. Could be view just to the current document or editor. We can use this information User and User Authorization DB.
Export-Import Document Service
If you want to export or import a document this service will be in handle over here. Connecting NoSQL and RDBMS DB. It could need comments while export documents.
We have RDBMS DB. Because we need to be consistent and we need ACID property there.
Like users, even the Document ID and they refer to the document and all the different resources.
If we have some change in a document we need ACID (Atomicity, Consistency, Isolation, Durability) or a transactional way to ensure change is completed. It didn’t complete this transaction will be very confusing matching to the diff for Operational Transformation.
Like we want to back former date documents. We make sure this transaction is complete. And we can continue some updates on the former documents. Otherwise, we can not update these former documents.
Time Series DB
Time-series data is a sequence of data points collected over time intervals, giving us the ability to track changes over time. Time-series data can track changes over milliseconds, days, or even years.
There are many other kinds of time-series data, but regardless of the scenario or use case, all time-series datasets have 3 things in common:
- The data that arrives is almost always recorded as a new entry
- The data typically arrives in time order
- Time is a primary axis (time-intervals can be either regular or irregular)
In other words, time-series data workloads are generally “append-only.”
Simply put: time-series datasets track changes to the overall system as INSERTs, not UPDATEs.
Some DBs: InfluxDB, ElastichSearch
We have 3 clients and one sharing document. A user wants to reach the former 3 days ago document.
You always make sure that there is a state which is maintained on the server because this client goes offline anytime, other clients can diverge at any time. We need to make sure we are actually maintaining the state of the document and all the histories or the updates are kind of saved in someplace. In the Time Series DB, we can get a timeline of operations, and also we can track what user has modified what particular part of the document.

Websockets – TCP connection
1-) Real-Time
2-) Light Weight
HTTP, Long Pooling, AJAX not efficient. Because takes little time.
We don’t need to ask the server ‘Are there any changes.’
We just send and receive.
When the first time a user opens the document, we actually hit the API gateway as far as if the has permission, the user will get a session established once he/she goes to the edit mode and he gets Websocket. WE can use NodeJs WebSocket which is established from the browser to the server always on so now the user can efficiently keep on sending small operations as when the user wants then receive the updates from other clients from the server immediately as soon as they broadcast it.
We are using the Operational Transformation design in our case. We are expecting the message size to be very small but numerous events so Websockets are best for those kinds of operations even in Node Js hands as well.
Operation Queue
All these operations should be ordered in a queue because 2 guys have to send the same operation on the same line or same char at the same time you still or the service should still prioritize one over the other so we need to it’s better to put it in the queue and then keep on in just as in when the operations from all the clients for that particular document keeps coming in.
Session or Authorative MS
We have an operations queue here where all the operations are in the Queue over here and the session server will keep on interesting both operations and it keeps its own state of the document. That acts as a single source of truth.
Time Series DB
Also, it keeps on saving a copy of the history of our operations into the Time Series DB. Want to deliver it back to a particular version or if you want to check who edited this particular line or this particular word we can easily get that information Time Series DB. We are using Time Series DB but if you want you can actually use SQL or another like Tree kind of representation a graph representation of how this particular line changes or document changed you can actually use graph Db as well.
Cloud Storage
If you want to convert a document to PDF or HTML or any format or if you want to share a link obviously you download it you need to talk bout it to cloud storage and that link will be provided to the user via email for them to download so you can use the cloud storage there or save that in and exporting document.
Microservices Structure
- Simplicty / modularity
- Faster to develop & understand
- Different tech stack
- Scaling easy
